Лабораторная работа 4.2 (Model serving)
Данную лабораторную работу рекомендуется выполнять в группах 1-3 человек.
1. Необходимо ознакомиться с материалом из лекции 5 и интегрировать обученную модель для детекции и распознания лиц в микросервисы на BentoML. Сервера должны по REST API на входное изображение возвращать JSON с информацией о детекциях (координаты рамки объекта, класс (можно не возвращаться, так как он один), и уверенность сети в предсказании), сервер для распознания может возвращать вектор эмбеддинга лица в бинарном виде. Фреймворк для запуска модели может быть любым (например PyTorch, PyTorch JIT, Tensorflow или ONNX). В качестве альтернативы можно использовать отечественный аналог для BentoML: Aqueduct или альтернативное более простое решение LitServe. Готовые модели для детекции и предсказания эмбеддинга лиц можно взять из библиотеки InsightFace. Но также можно воспользоваться и более современными детекторами, например готовая реализация для лиц: YOLOv6-Face.
2. Для хранения информации о пользователях необходимо использовать любую легковесную БД, например SQL-Lite (инструкция по работе на Python). Результаты работы модели распознания лиц должны хранится в специальных базах, позволяющих производить эффективный поиск по векторам. В качестве такой базы можно использовать Milvus (документация по установке). В используемой таблице необходимо добавить колонку для хранения вектора из Milvus, например назвав её milvus_id.
3. Для взаимодействия с сервисом желательно реализовать главный сервис, который будет связывать логику всех используемых микросервисов и обрабатывать запросы. Для реализации можно выбрать Fast API или Flask. Fast API может стать лучшим выбором, так как он сразу генерирует документацию и тестовое API по средствам swagger. Сервер должен содержать следующие методы:
- /api/new_person/ - добавление человека в базу, должен принимать изображение в бинарном виде и имя человека в загловке запроса, также он возвращает ошибку, если человек уже есть в базе
- /api/get_person/ - поиск человека по базе, возвращает имя человека или некоторое пустое значение, если человека в базе нет
4. Для демонстрации работы построенного микросервиса следует реализовать web интерфейс на фреймворке Streamlit. Интерфейс должен включать следующий функционал:
- Возможность загрузки изображения пользователем
- Визуализацию результата предсказания модели (выводить просто изображения с отрисовкой и имя человека из базы)
- (опционально) Можно реализовать функционал по добавлению лица в базу из пользовательского интерфейса
Также необходимо запускать микросервисы (это часть с BentoML / Aqueduct и сервис с главным API) внутри Docker.
Схема решения представлена ниже: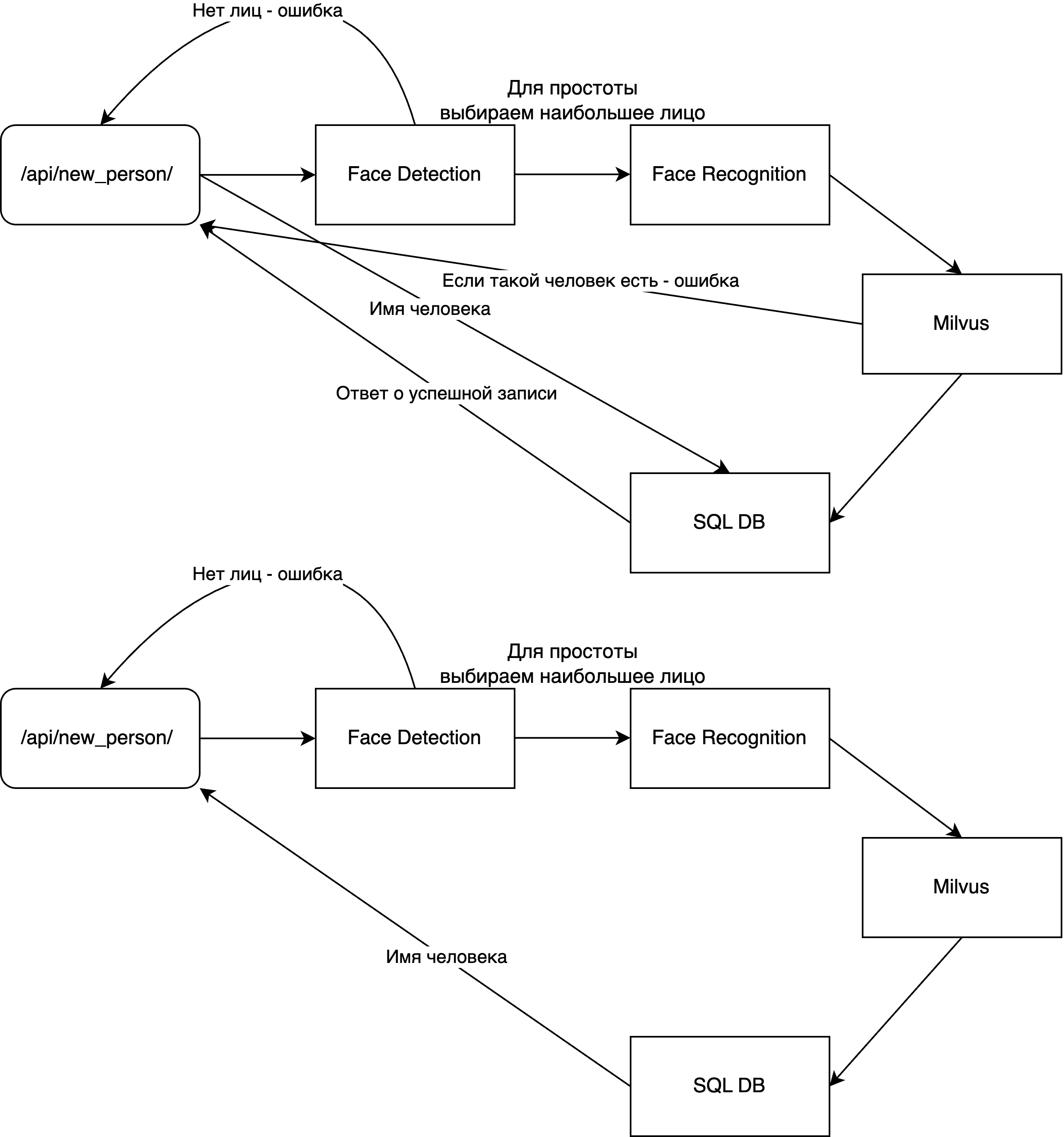
Допускается более простая реализация без реализации микросервисов, но будет оцениваться в 10% от максимального балла.
1. Можно запускать модели напрямую в Streamlit, также необходимо их кэшировать в фреймворке, чтобы не допускать множественных определений экземпляров моделей.
2. Вместо БД можно использовать словари json / yaml и осуществлять их загрузку и обновление напрямую в Streamlit, не забывая про кэшироваие.
Можно подготовить реализацию по поиску в массиве данных через модели в scikit-learn или воспользоваться легковесной библиотекой для векторного поиска Faiss.
Требование к докеризации решения сохраняется.
Альтернативным решением лабораторной, но за 25% от её баллов может выступать задача интеграции решения, полученного в лабораторной работе 4.1 в микросервис для запуска моделей на BentoML или LitServe с запуском веб-интерфейса на фреймворке Streamlit.